

Groundtruth |
Activity Interpretation |
Groundtruth |
Activity Interpretation |
||
Watch Laptop |
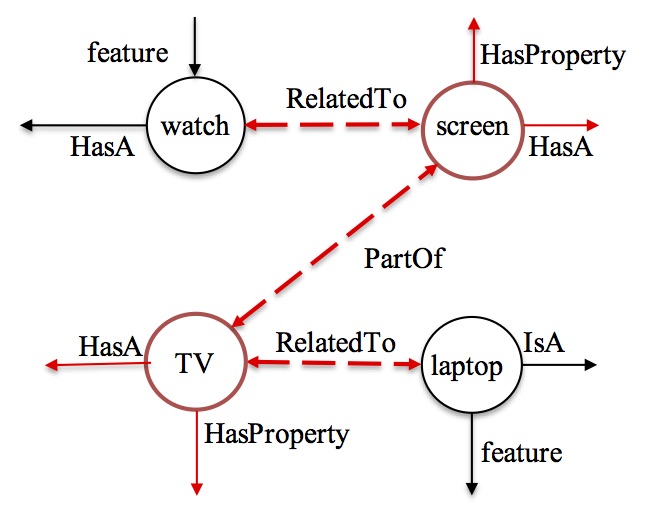
Watch Laptop |
A person is playing a guitar. |
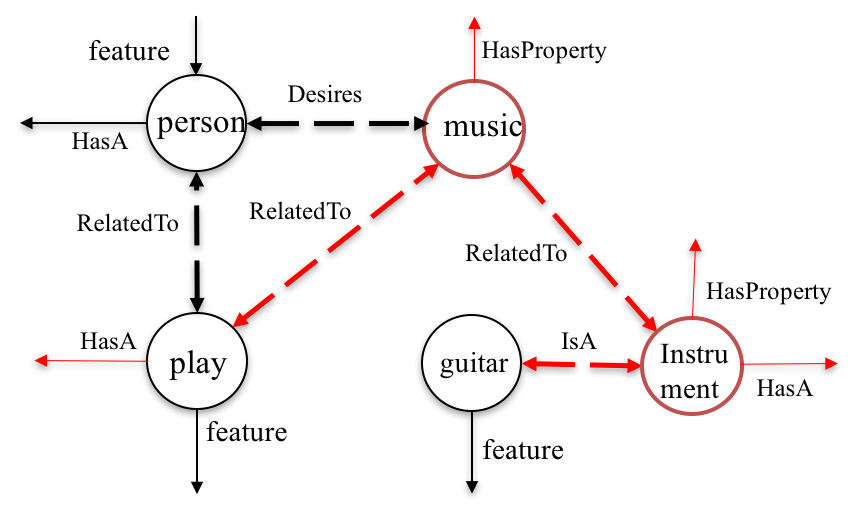
A person is playing a guitar. |
A Perceptual Prediction Framework for Self Supervised Event Segmentation
Sathyanarayanan Aakur, Sudeep Sarkar
Arxiv, 2018, 1811.04869.
[pdf]
Fine-grained Action Detection in Long Surveillance Videos
Sathyanarayanan Aakur, Daniel Sawyer, Sudeep Sarkar
Workshop on Human Activity Detection in Multi-Camera, Continuous, Long-Duration Video (HADCV'19), Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, Hawaii [pdf](Coming Soon!)
Going Deeper with Semantics: Exploiting Semantic Contextualization for Interpretation of Human Activity in Videos
Sathyanarayanan Aakur, Fillipe DM de Souza, Sudeep Sarkar
Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, Hawaii [pdf]
Generating Open World Descriptions of Video using Commonsense Knowledge in a Pattern Theory Framework
Sathyanarayanan Aakur, Fillipe DM de Souza, Sudeep Sarkar
Quarterly of Applied Mathematics, 2019
[pdf]
On the Inherent Explainability of Pattern Theory-based Video Event Interpretations
Sathyanarayanan Aakur, Fillipe de Souza, Sudeep Sarkar
Book Chapter, Explainable and Interpretable Models in Computer Vision and Machine Learning in the Springer Series on Challenges in Machine Learning, 2019
[pdf]
An Inherently Explainable Model for Video Activity Interpretation
Sathyanarayanan Aakur, Fillipe DM de Souza, Sudeep Sarkar
AAAI Workshop On Reasoning and Learning for Human-Machine Dialogues (DEEP-DIAL18), February 2018.
[pdf]
Towards a Knowledge-based approach for Generating Video Descriptions
Sathyanarayanan Aakur, Fillipe DM de Souza, Sudeep Sarkar
In Proceedings of the Conference on Computer and Robot Vision, Edmonton, Alberta, Canada, May 2017.
[pdf]
Spatially coherent interpretations of videos using pattern theory
Fillipe DM de Souza, Sudeep Sarkar, Anuj Srivatsava, Jingyong Su
In Proceedings of the International Journal of Computer Vision (IJCV), 2017.
[pdf]
Building semantic understanding beyond deep learning from sound and vision
Fillipe DM de Souza, Sudeep Sarkar, Anuj Srivatsava, Jingyong Su
In Proceedings of the International Conference on Pattern Recognition (ICPR), 2016.
[pdf]
Temporally Coherent Interpretations for Long Videos Using Pattern Theory
Fillipe DM de Souza, Sudeep Sarkar, Anuj Srivatsava, Jingyong Su
In Proceedings of the Conference on Pattern Recognition and Computer Vision (CVPR), 2015.
[pdf]
Pattern Theory-Based Interpretation of Activities
Fillipe DM de Souza, Sudeep Sarkar, Anuj Srivatsava, Jingyong Su
In Proceedings of the International Conference on Pattern Recognition (ICPR), 2014.
[pdf]