

Action Localization through Continual Predictive Learning

The problem of action recognition involves locating the action in the video, both over time and spatially in the image. The dominant current approaches use supervised learning to solve this problem, and require large amounts of annotated training data, in the form of frame-level bounding box annotations around the region of interest. In this paper, we present a new approach based on continual learning that uses feature-level predictions for self-supervision. It does not require any training annotations in terms of frame-level bounding boxes. The approach is inspired by cognitive models of visual event perception that propose a prediction-based approach to event understanding. We use a stack of LSTMs coupled with CNN encoder, along with novel attention mechanisms, to model the events in the video and use this model to predict high-level features for the future frames. The prediction errors are used to continuously learn the parameters of the models. This self-supervised framework is not complicated as other approaches but is very effective in learning robust visual representations for both labeling and localization. It should be noted that the approach outputs in a streaming fashion, requiring only a single pass through the video, making it amenable for real-time processing. We demonstrate this on three datasets - UCF Sports, JHMDB, and THUMOS'13 and show that the proposed approach outperforms weakly-supervised and unsupervised baselines and obtains competitive performance compared to fully supervised baselines. Finally, we show that the proposed framework can generalize to egocentric videos and obtain state-of-the-art results in unsupervised gaze prediction.
Action Localization Results
We present additional qualitative results for all three datasets - UCF Sports, JHMDB, and THUMOS'13. We show both our best case and worst case results. Each illustration (GIF) shows the predictions for each input video from each dataset. Below each illustration is the class and the average IoU (across the entire video) of the predictions. The worst case performance in each dataset is shown in the last column of their respective rows.
Ground truth bounding box is illustrated in red, the best prediction is illustrated in blue and other proposals are illustrated in green. The attention point is illustrated in solid blue rectangle.
UCF Sports

Skateboard
Av. IoU: 0.788786

Swing Bench
Av. IoU: 0.762009

Golf Swing
Av. IoU: 0.676564

Walk
Av. IoU: 0.618025

Riding Horse
Av. IoU: 0.676564
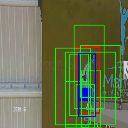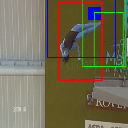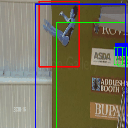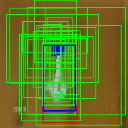
Diving
Av. IoU: 0.345489
JHMDB

Brush Hair
Av. IoU: 0.777907

Clap
Av. IoU: 0.747944

Pour
Av. IoU: 0.730603

Walk
Av. IoU: 0.676026
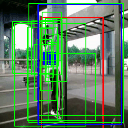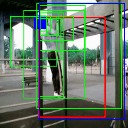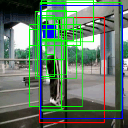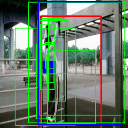
Pull up
Av. IoU: 0.634874

Run
Av. IoU: 0.260543
THUMOS'13

Rope Climbing
Av. IoU: 0.75471

Ice Dancing
Av. IoU: 0.678295
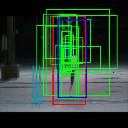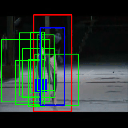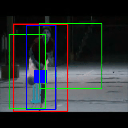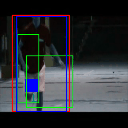
Cricket Bowling
Av. IoU: 0.613127

Salsa Spin
Av. IoU: 0.562

Run
Av. IoU: 0.250803
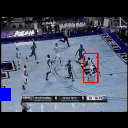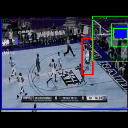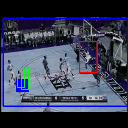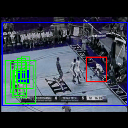
Pull up
Av. IoU: 0.07861
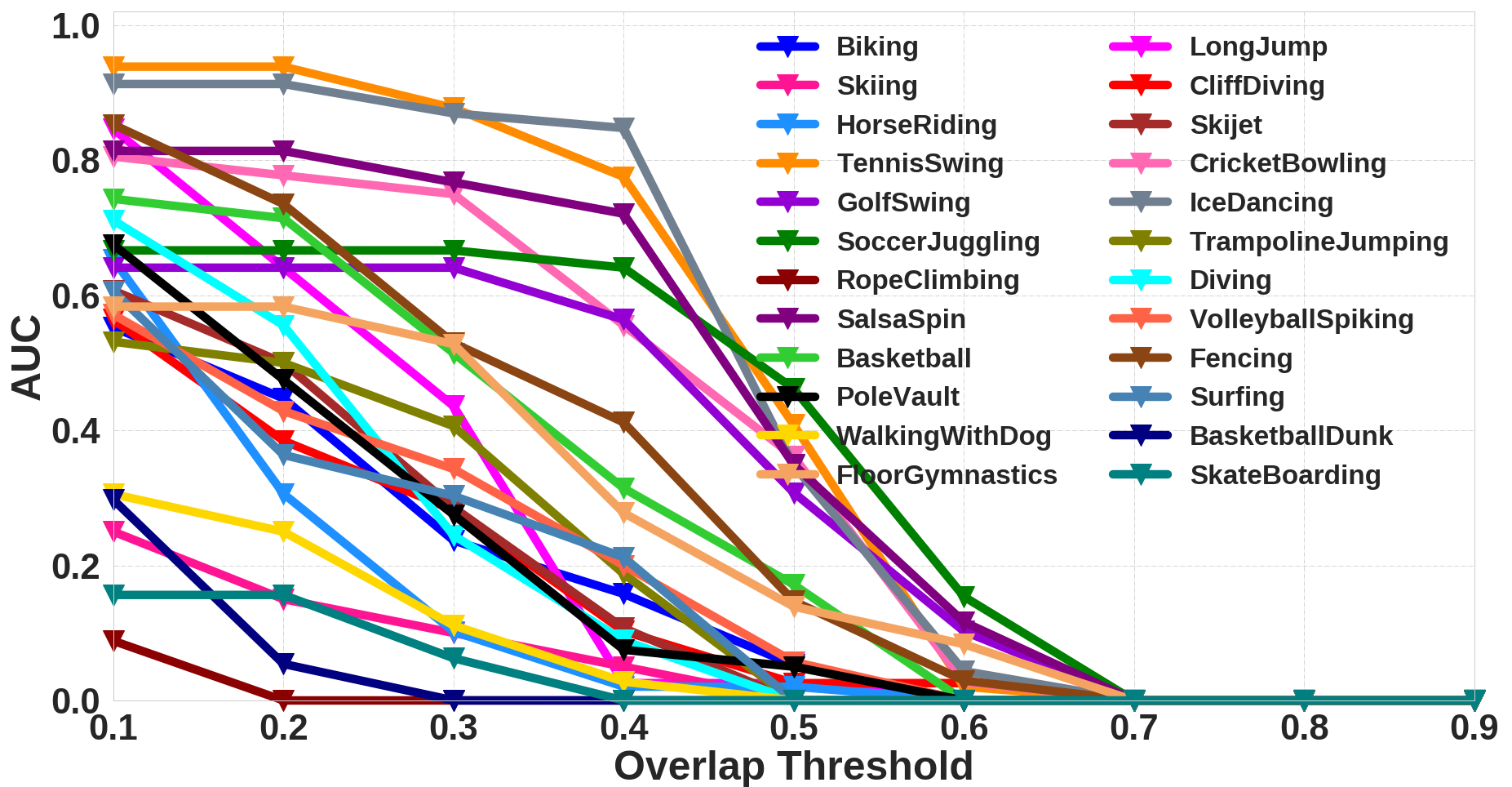
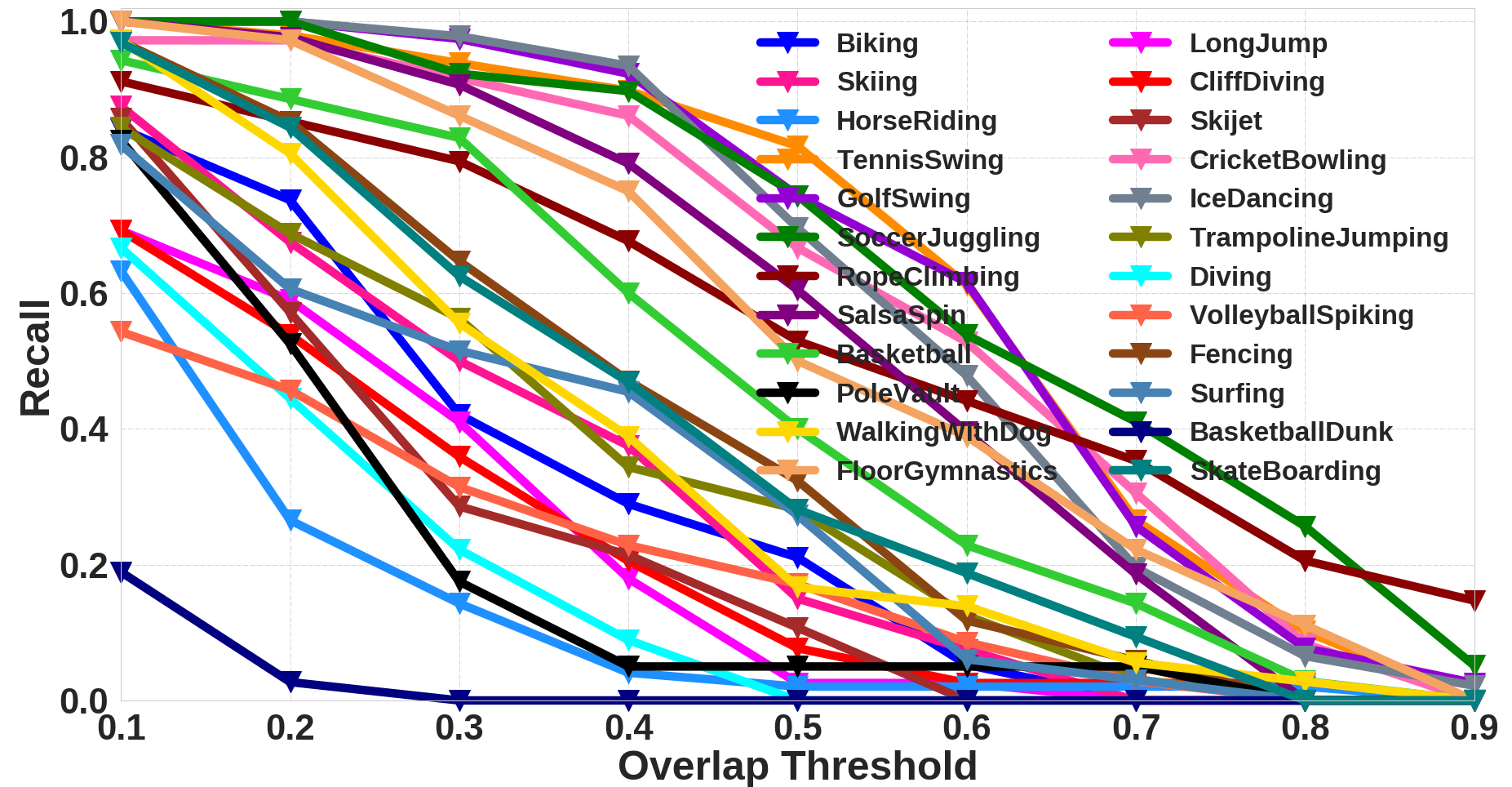
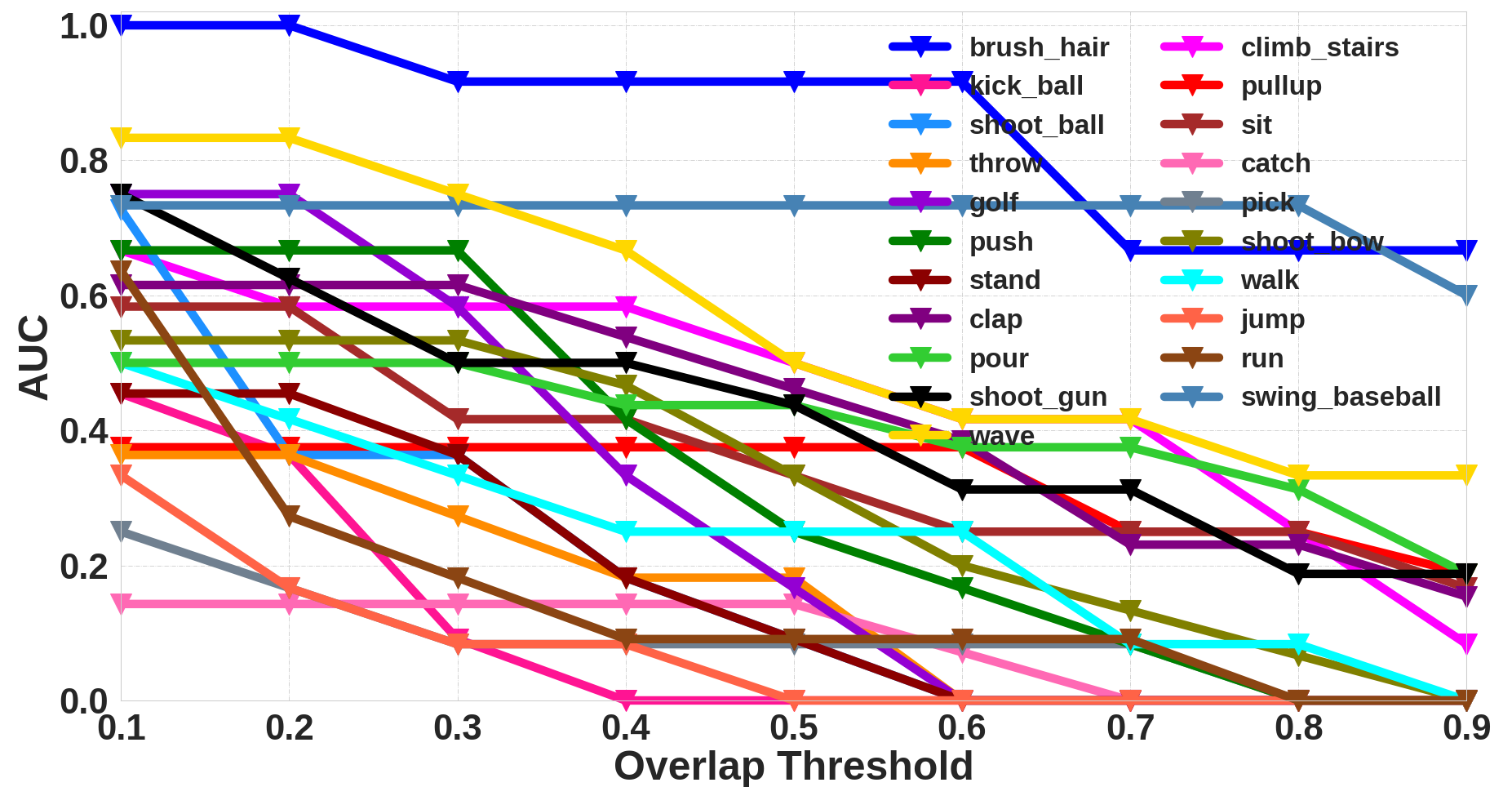
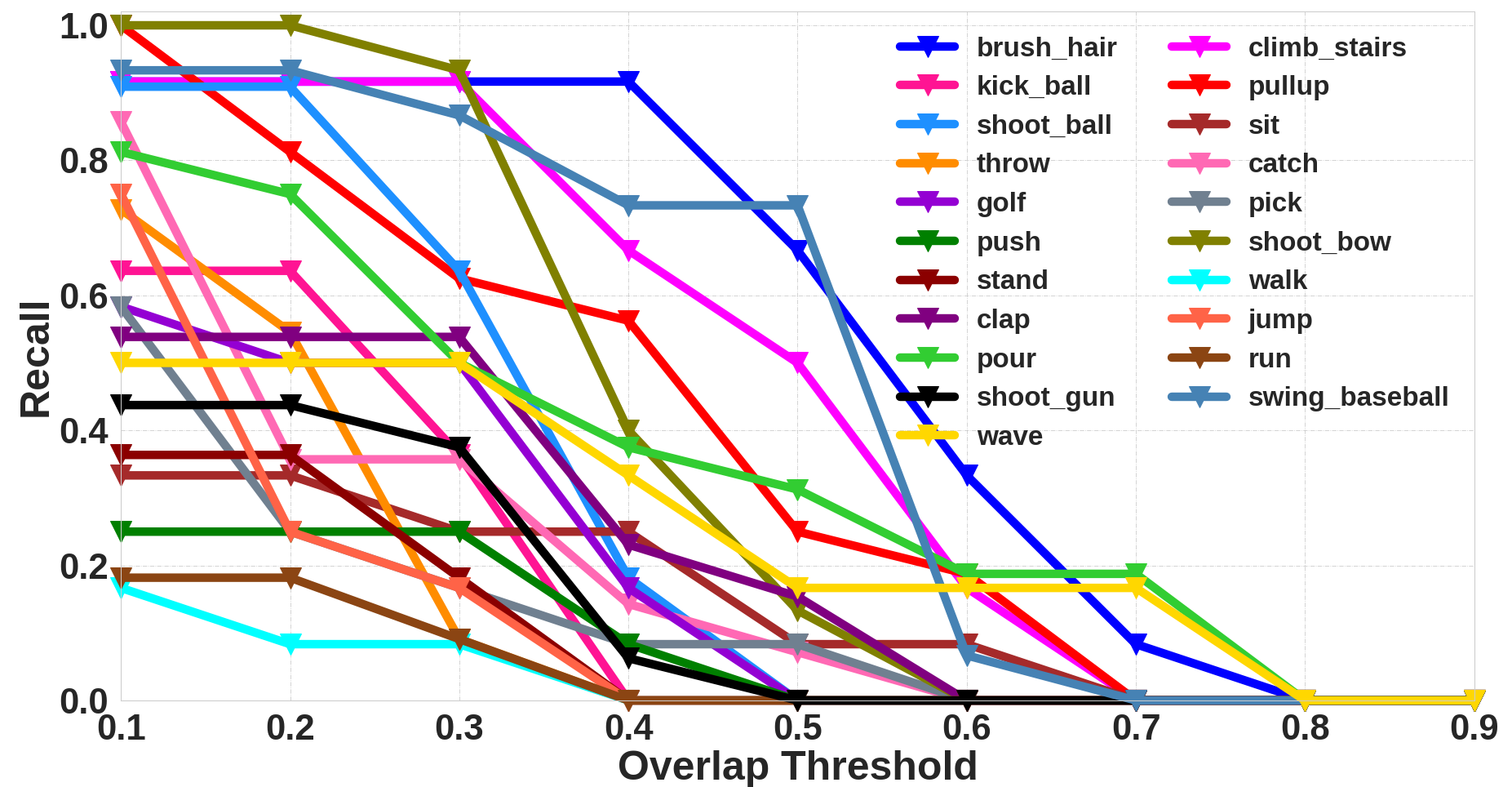
Additional Qualitative Analysis
We also present additional qualitative analysis of the proposed approach. We analyze the class-wise AUC and Recall for each dataset. This is similar to the plots shown in Figure 3 (a-b) in the main paper.
Class-wise AUC for THUMOS'13
Class-wise Recall for THUMOS'13
Class-wise AUC for JHMDB
Class-wise Recall for JHMDB
Bibtex
@misc{aakur2020action,
title={Action Localization through Continual Predictive Learning},
author={Sathyanarayanan N. Aakur and Sudeep Sarkar},
year={2020},
eprint={2003.12185},
archivePrefix={arXiv},
primaryClass={cs.CV}
}